First public coding piece
First public coding piece
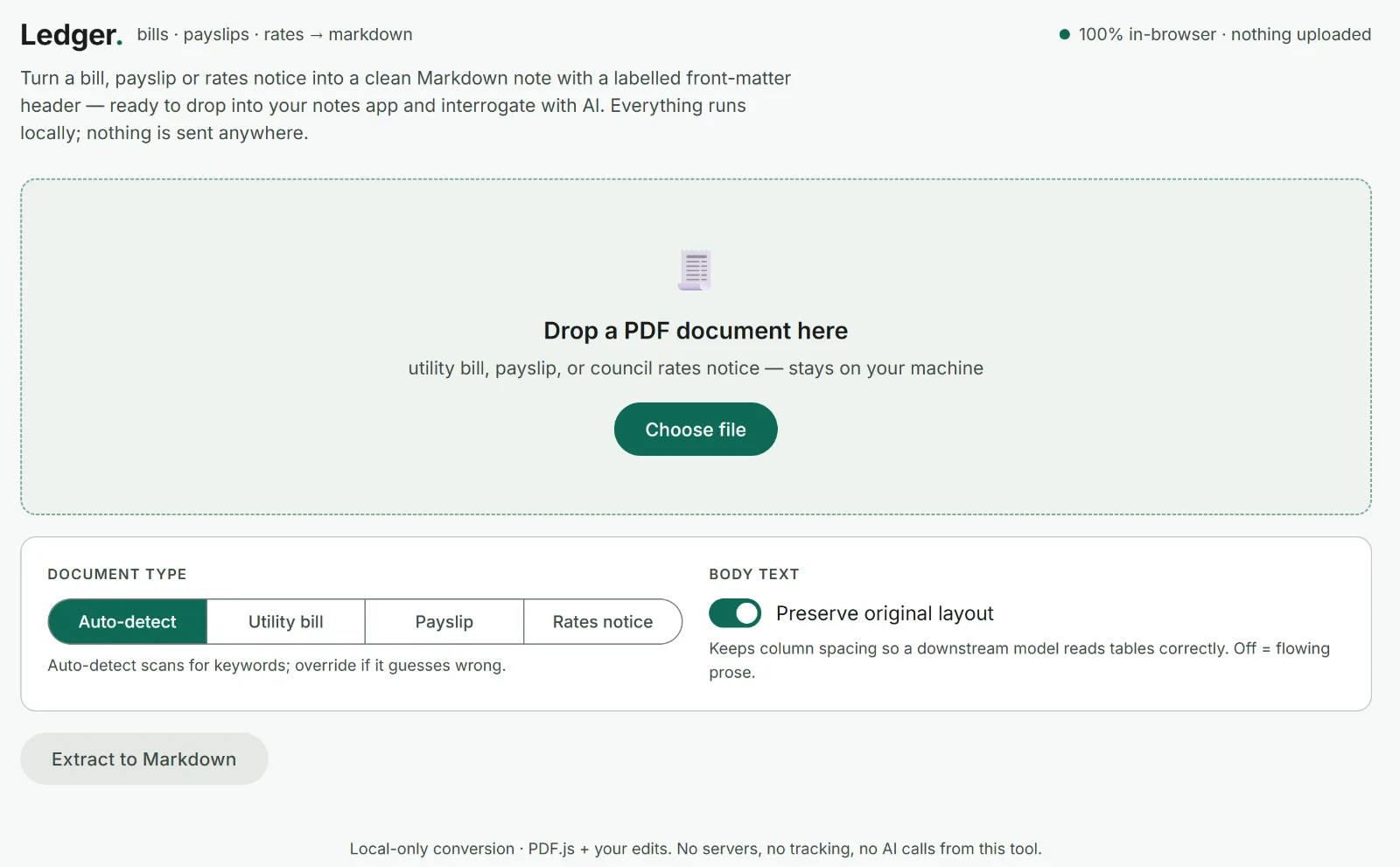
Today I published my first public coding piece on GitHub; it's a tool to convert PDF files into Markdown and JSON format for easier interrogation by AI.
I'm not a coder and this personal milestone was only made possible by AI itself.
I came across a similar tool on Reddit, called LiteDoc, which I've forked with modifications.
Specifically, my tool called Ledger is designed to convert Australian utility bills, rates notices and payslips into a format which AI can read and analyse more easily and less expensively than PDF files.
It will also convert general PDF documents, and make them readable to AI, as long as they contain text. Ledger is only for use on personal devices.
Example use case: After uploading several electricity bills in this format, ask AI to report on your average bill, cost per kWh and usage. It will use fewer tokens than asking the same question with PDF files.
AI assistance
I started with Claude Chat (I have a paid account) to see if the LiteDoc code could be cloned and forked to support my use case.
I then went to Claude Code to make the changes, including a light material design. Claude also helped write the GitHub readme file and advised on privacy and security.
I've created several other apps using Claude, Gemini and Deepseek, and generally I've found Claude to be the best. Sometimes it reviews code from other models and identifies security issues and bug fixes.
My private apps include a personal organiser, personal finance, home utilities tracker, vehicle expenses, notes, voice recordings, and file storage.
I might make some of these public, or commercialise them, after more robust testing and security checks.
Are they my apps, or AI? I bring to the table some basic knowledge of HTML, CSS and PHP, as well as design experience and years of user perspective.
Theoretically, anyone could make the apps that I've made and some have, but they're either not fit for my purpose or they cost money to use.
I've found it more cost-effective and more useful to create my own apps through experimentation.
Coding is a new hobby
Coding has become an interesting hobby for me. As an early adopter of technology, I've always tried to be at the forefront of using new tools, whether it was the Internet, web design or mobile phones.
Luckily I never bought a Betamax video player, although I did pay way too much once for a video camera that was superseded by ordinary cameras and mobile phones within a few years.
Here's the full readme file for my first published utility:
Ledger PDF conversion
A local-only, browser-based tool that converts Australian utility bills, payslips, and council rates notices into clean Markdown notes with structured YAML front-matter — ready to import into your notes app and interrogate with AI.
Nothing is uploaded. Everything runs in your browser.
---
What it does
Drop a PDF onto the page and Ledger extracts the key financial fields into a labelled front-matter header, with the full document text below. It outputs two formats:
Markdown
.md) — for Obsidian, Apple Notes, or any Markdown-based workflowJSON
.json) — structured for direct import into notes apps that store content in a database (the JSON format matches the Organiser/Firebase notes import schema, with a compact summary line positioned so AI assistants can read all key figures within their per-note preview limit)
Ledger handles the extraction step only — AI querying happens with your AI assistant of choice, using the structured output as its source material.
---
Supported document types
Auto-detected by keyword scoring, or set manually:
| Type | Extracted fields |
|---|---|
| Utility bill | Provider, account, period, kWh usage, avg daily usage, amount due, due date |
| Payslip | Employer, pay period, pay date, gross, tax, super guarantee, salary sacrifice super, net, YTD gross |
| Rates notice | Council, assessment number, financial year, capital improved value, rateable value, amount due, due date |
| General document | Date, amount |
Detection is tuned for Australian providers, councils, and terminology (NMI, PAYG, SG, kilolitre, etc.).
---
How to use
1. Save doc-to-markdown.html to your machine
2. Open it in any modern browser — no server, no install
3. Drop or choose a PDF
4. Review and correct the extracted fields
5. Download .md, .json, or copy the Markdown to clipboard
Keep a copy on each machine you use. There is no hosted version.
---
Features
- 100% local — PDF.js runs entirely in-browser; no file ever leaves your machine
- Auto-detection — weighted keyword scoring identifies document type
- Layout-preserving extraction — optional column-spacing mode helps AI models read tables correctly
- Heading detection — font size metadata promotes section headers to Markdown ##
- Text normalisation — ligatures fi→fi), smart quotes, en/em dashes, non-breaking spaces cleaned automatically
- Scanned PDF warning — alerts if no text layer is found
- Editable front-matter — review and correct any field before export; add custom fields
- JSON export — summary line placed at the top of note content so AI assistants see all key figures within their context preview window
---
Modifications from LiteDoc
This tool began as a fork of [LiteDoc](https://github.com/0xovo/LiteDoc) by [0xovo](https://github.com/0xovo) and has been substantially modified:
- Domain-specific extraction — heuristic field extraction for Australian utility bills, payslips, and council rates notices, with weighted keyword detection and regex patterns tuned to local providers and terminology
- JSON export — structured output for notes apps with a compact summary line optimised for AI context windows
- Material Design 3 UI — restyled with Inter + JetBrains Mono, MD3 tonal colour system, pill buttons, underline tabs, and tonal surface hierarchy; warm editorial aesthetic replaced with a clean productivity-tool look
- Font size–based heading detection — items significantly above the page median font size are promoted to ## headings in flow output
- Improved column spacing — lastEnd estimate scales by actual item font size rather than a fixed constant
- Text normalisation pass — ligature and encoding artefact cleanup applied to every extracted text item
- Scanned PDF detection — warns when extracted text is near-empty
- Separate super fields — super guarantee and salary sacrifice are extracted into distinct fields with correctly prioritised label matching
---
Dependencies (all CDN, no install)
- [PDF.js](https://mozilla.github.io/pdf.js/) — PDF parsing (Mozilla, Apache 2.0)
- [marked](https://marked.js.org/) — Markdown rendering for the preview tab (MIT)
- [Inter](https://rsms.me/inter/) — UI font (SIL Open Font Licence)
- [JetBrains Mono](https://www.jetbrains.com/legalforms/fonts/) — monospace font (SIL Open Font Licence)
---
Notes
- Field extraction is heuristic — always review the front-matter before trusting numbers
- Scanned (image-only) PDFs produce no output; a text layer is required
- Tuned for Australian documents; results will vary for non-AU formats
- The original PDF remains your legal record — the extracted note is a working copy for search and AI queries
Download and use
If you would like to download and use this utility, go to the public GitHub repository. Either click on code in the top toolbar to the right and download the zip file, or right click on the doc-to-markdown.html file and save it somewhere on your machine. Open it in your browser of choice to use.
Leave a comment
Your email address is strictly confidential and will never be displayed publicly.